一、Kafka架构介绍
一个典型的Kafka集群中包含若干Producer,若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
kafka架构
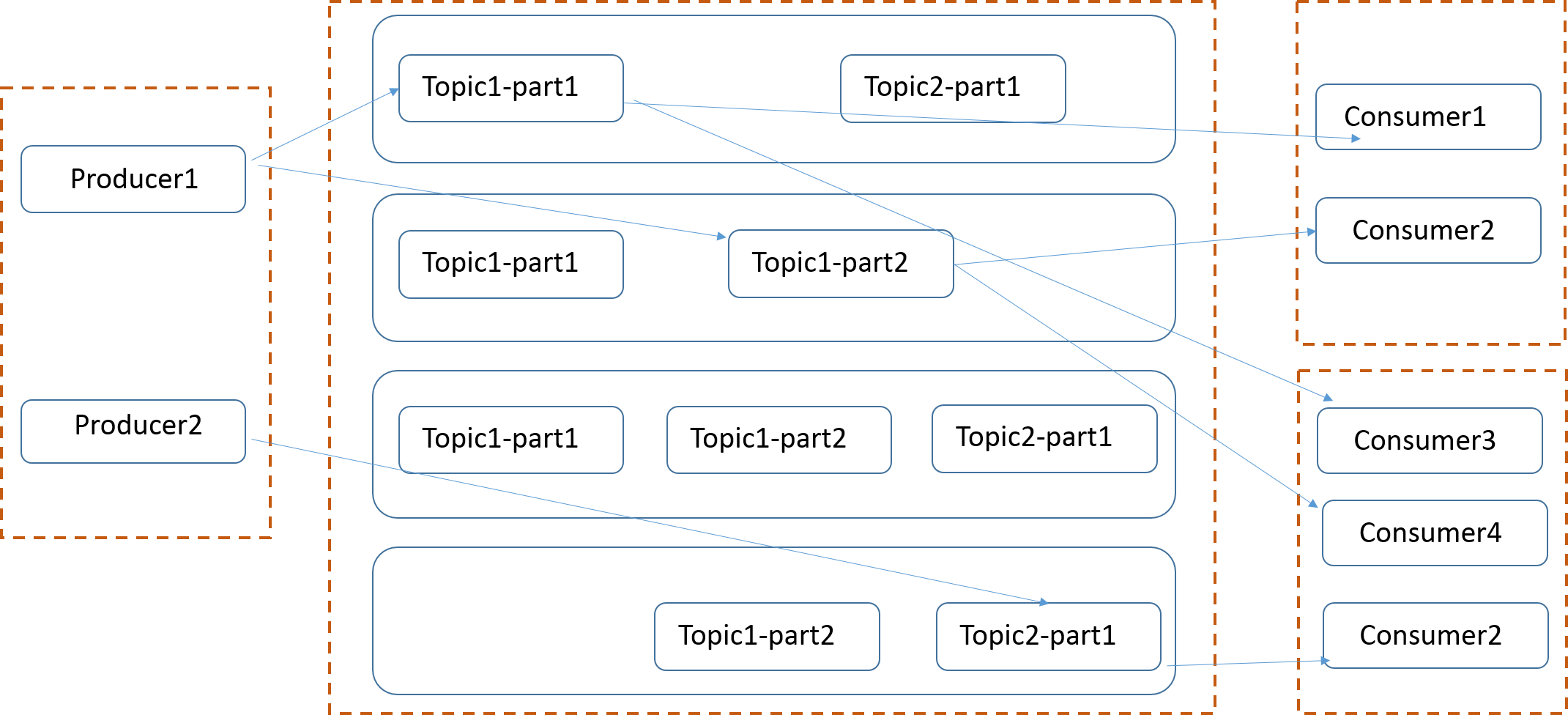
二、Topics和Partition的关系
主题(topic):一个 topic 里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
分区(partition):每个 topic 都可以分成多个 partition,每个 partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高
三、Consumer Group
每一个consumer实例都属于一个consumer group,每一条消息只会被同一个consumer group里的一个consumer实例消费。(不同consumer group可以同时消费同一条消息)
很多传统的message queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证queue的长度比较少,提高效率。而如上文所将,Kafka并不删除 已消费的消息,为了实现传统message queue消息只被消费一次的语义,Kafka保证保证同一个consumer group里只有一个consumer会消费一条消息。与传统message queue不同的是,Kafka还允许不同consumer group同时消费同一条消息,这一特性可以为消息的多元化处理提供了支持。实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。
四、push vs pull
kafka采用的是传统的数据由producer推送给broker,然后由consumer从broker拉去的机制
五、基本操作
启动ZooKeeper
1
bin/zookeeper-server-start.sh config/zookeeper.properties
启动Kafka
1
bin/kafka-server-start.sh config/server.properties
创建主题
1
2bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-World刚刚创建了一个名为 `Hello-World的主题,其中包含一个分区和一个副本因子
获取主题列表
1
bin/kafka-topics.sh --list --zookeeper localhost:2181
生产者发送消息
1
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-World
然后就可以在终端键入消息
消费者消费消息.
1
2bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-World
--from-beginning